LLMs are revolutionizing document extraction by shifting from rigid, coordinate-based "zonal OCR" to semantic understanding, allowing them to extract data from complex documents without the need for pre-defined templates. By utilizing multimodal capabilities and contextual reasoning, these models can reason through complex agreements, interpret nuanced language, apply corrections based on handwritten comments, and link related information across dozens of pages. This collapses traditional multi-step pipelines into a single process that can output structured data (like JSON) directly, making LLMs the superior choice for handling the nuance of highly varied financial documents where traditional pattern matching fails.
While LLMs are excellent at understanding context, reasoning through complex documents, and extracting a standardized taxonomy, incorporating Document AI into engineering workflows has created a new kind of technical debt. Every change to consuming systems results in a schema change, and bugs and rule changes have to be incorporated as prompt changes. When a schema changes or an extraction prompt needs a tweak, the ripple effects often force teams to start over, re-labeling thousands of documents and manually testing edge cases.
Obin’s Context Studio solves this by treating document extraction as the collaborative, version-controlled output of a systematic workflow. Instead of developers manually juggling Python scripts, YAML configs, and PDF viewers, they interact with a specialized Agent Harness (think Claude Code) that lives within the target deployment environment (and thus has the permissions to access sensitive data within regulated industry constraints).
The system is built on a modular three-plane architecture:
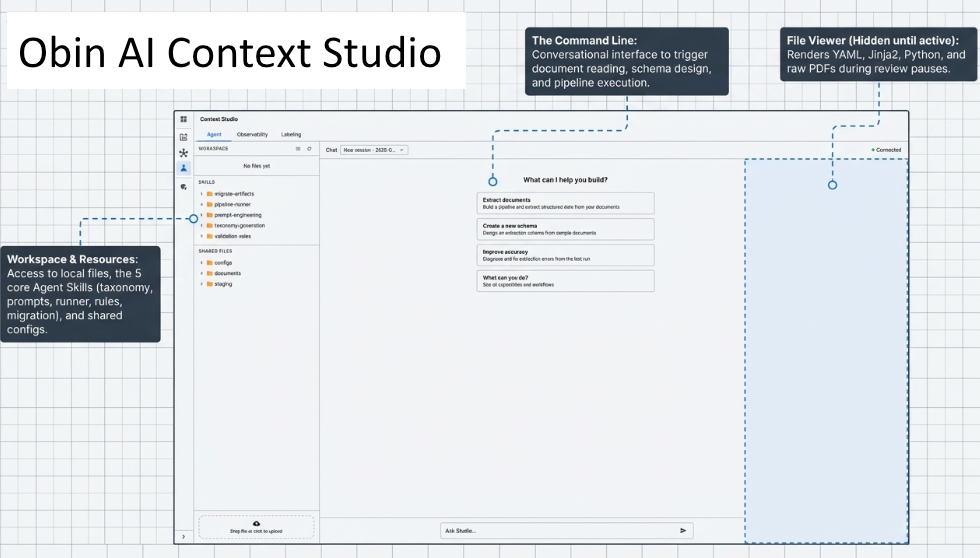
When a user encounters a new document type, they don't start from scratch. They tell the Agent: "I have a new asset servicing document." The Agent invokes its taxonomy-generation skill to propose a schema and its prompt-engineering skill to draft instructions. If a new downstream use case requires the schema to evolve from v8 to v8.1, the Agent uses a migrate-artifacts skill. This uses mathematical diff-checking to automatically map old ground-truth labels to the new format, saving weeks of manual human labor. Once the documents are labeled, the agent proactively communicates extraction accuracy, error patterns across documents, and how to fix them.
By moving away from static scripts and toward a specialized agentic environment, Context Studio provides three primary advantages for operations and dev teams:
Context Studio effectively moves Document AI extraction out of the realm of ad-hoc experimentation and into a disciplined, observable, and continually learning engineering workflow.≠